Breakthroughs of Future Technology
Our research introduces groundbreaking core algorithms that serve as the foundation for a future of seamless and intelligent human-computer interaction.
Error Prevention Mechanism
A critical challenge in developing any Human-Computer Interface (HCI) is minimizing errors during interaction. To ensure reliability and accuracy, the proposed Tonguage framework integrates a pipeline of error prevention mechanisms that optimize tracking and reduce unintended inputs.
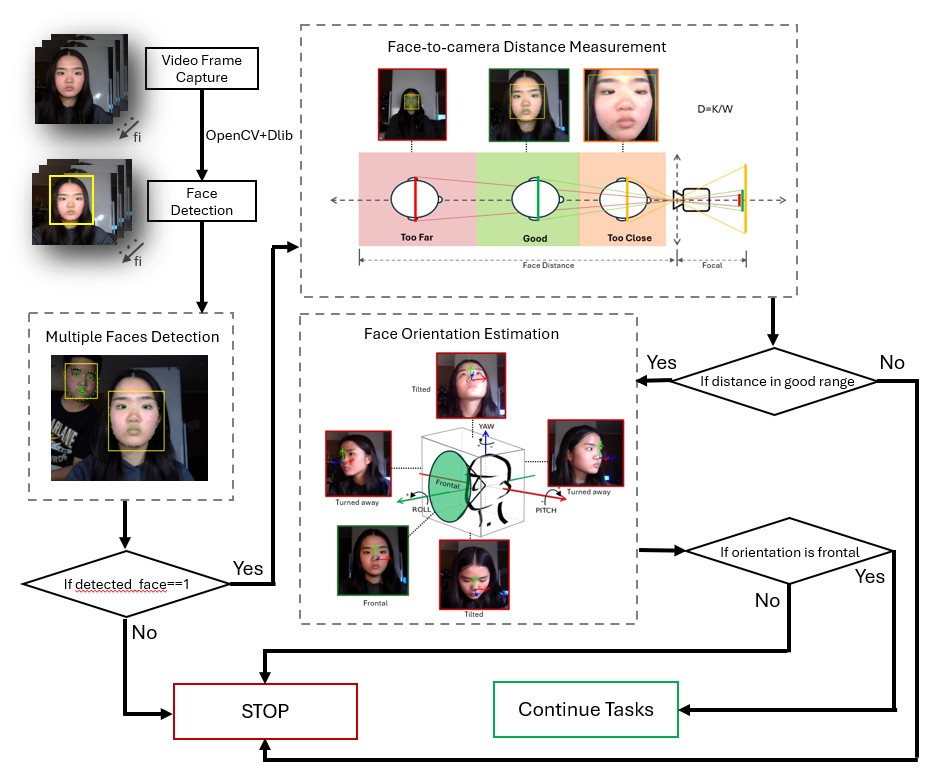
Our error prevention is built on two primary checks:
Identity Recognition
To ensure the system only responds to the intended user, Tonguage continuously scans the camera's view. If more than one face is detected, the system pauses input processing and alerts the user. This prevents interference from other people in the background, which is crucial for reliable operation in busy environments like clinics, family rooms, or public spaces. In the future, facial recognition could also be implemented to further verify user identity.

Focus Detection
To maintain precise tracking, focus detection ensures the user's face remains in an optimal alignment and distance from the camera. The system includes two key checks for this:
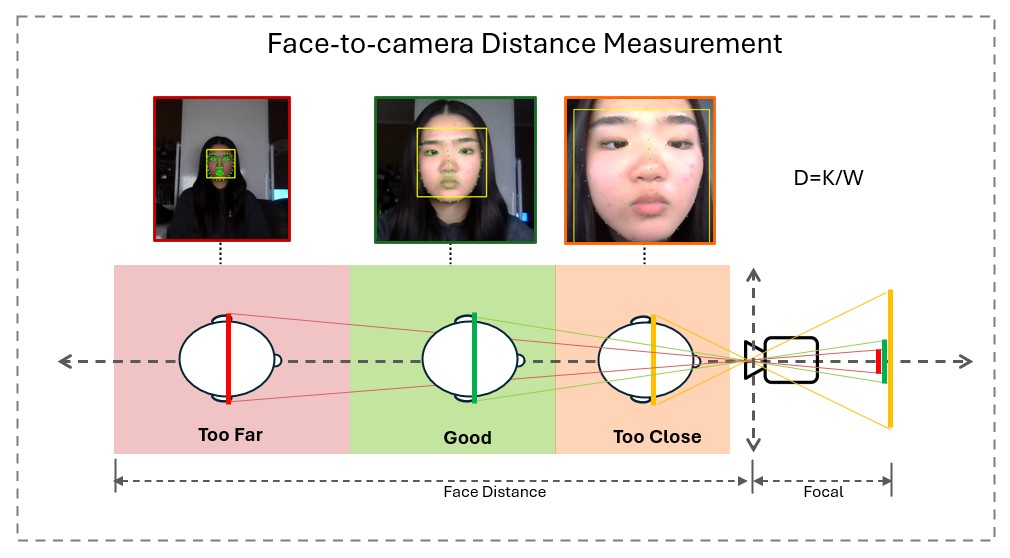
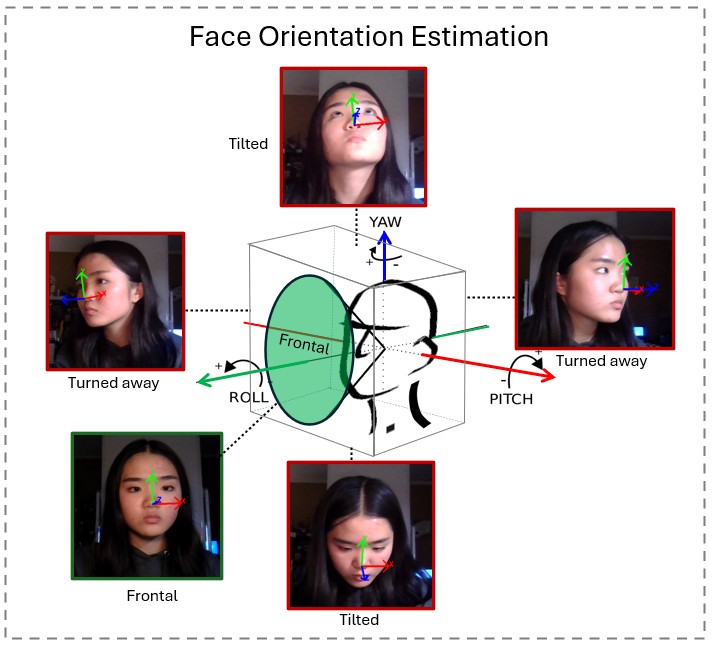
By incorporating these error prevention mechanisms, Tonguage improves input accuracy, system stability, and overall usability, ensuring a seamless and reliable user experience in diverse environments.
Tongue Segmentation Algorithm Using Adaptive Threshold in HSV Color Space
Tongue segmentation is a critical component of the experimental Tonguage system, as precise segmentation is essential for accurate gesture recognition and control. This algorithm employs an adaptive thresholding technique in the HSV color space to dynamically segment the tongue, accommodating variations in lighting conditions.
Advantages of HSV Color Space
In computer vision, the HSV (Hue, Saturation, Value) color space is often preferred over RGB for segmentation tasks due to its ability to separate intensity (brightness) from color information. In the RGB color space, brightness is distributed across all three channels (R, G, and B), making segmentation sensitive to illumination changes. In the HSV color space, most brightness-related information is stored in the Value (V) channel, while color details are preserved in the Hue (H) and Saturation (S) channels. This separation facilitates more robust segmentation, as the V channel can be analyzed independently to identify the tongue region.
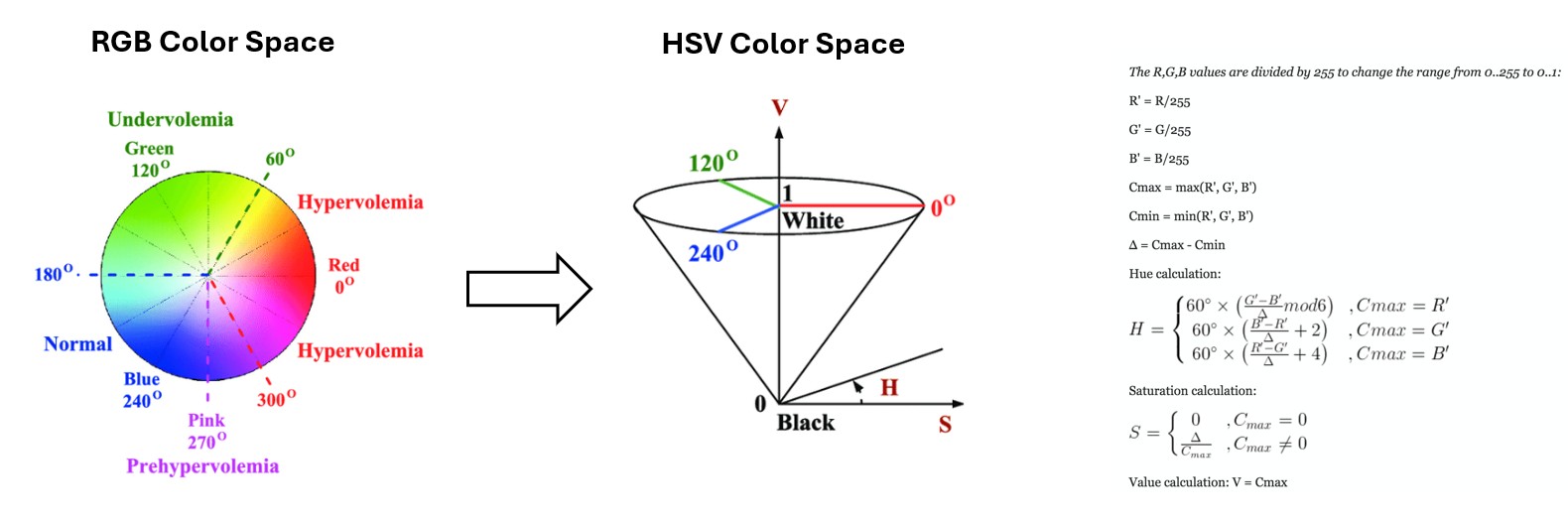
Adaptive Thresholding
A fixed threshold is ineffective for tongue segmentation due to varying lighting conditions across images. To address this, an adaptive threshold is used. First, the mouth region is expanded to capture more relevant pixels. Then, a histogram of V-channel intensities is computed, selecting the top 20% brightest pixels. The adaptive threshold is determined by the mean of these pixels.
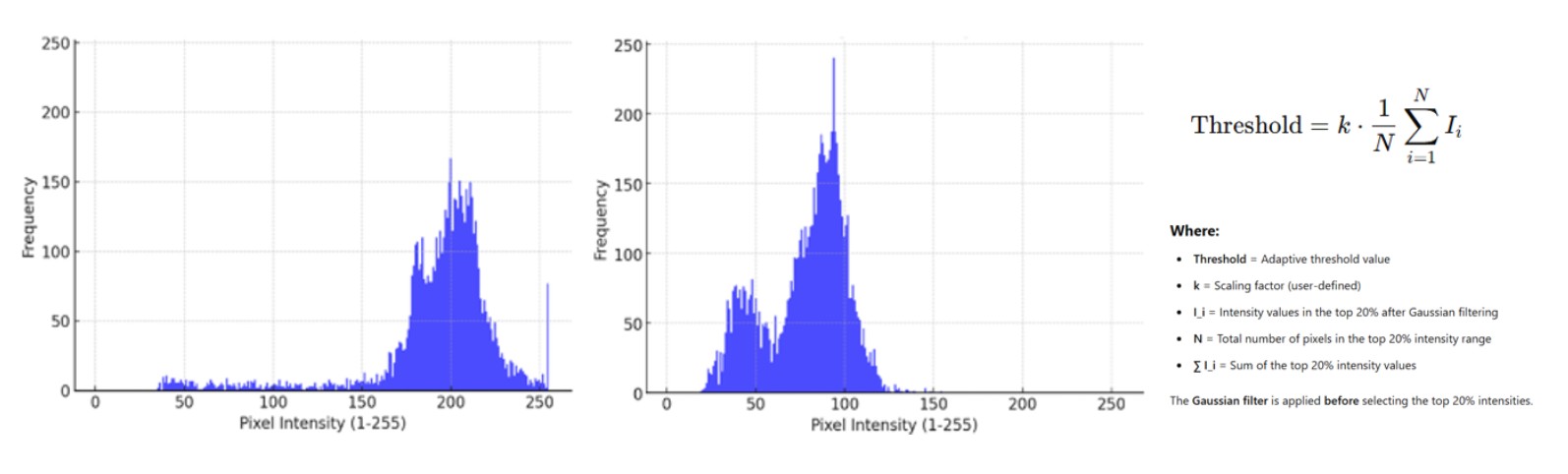
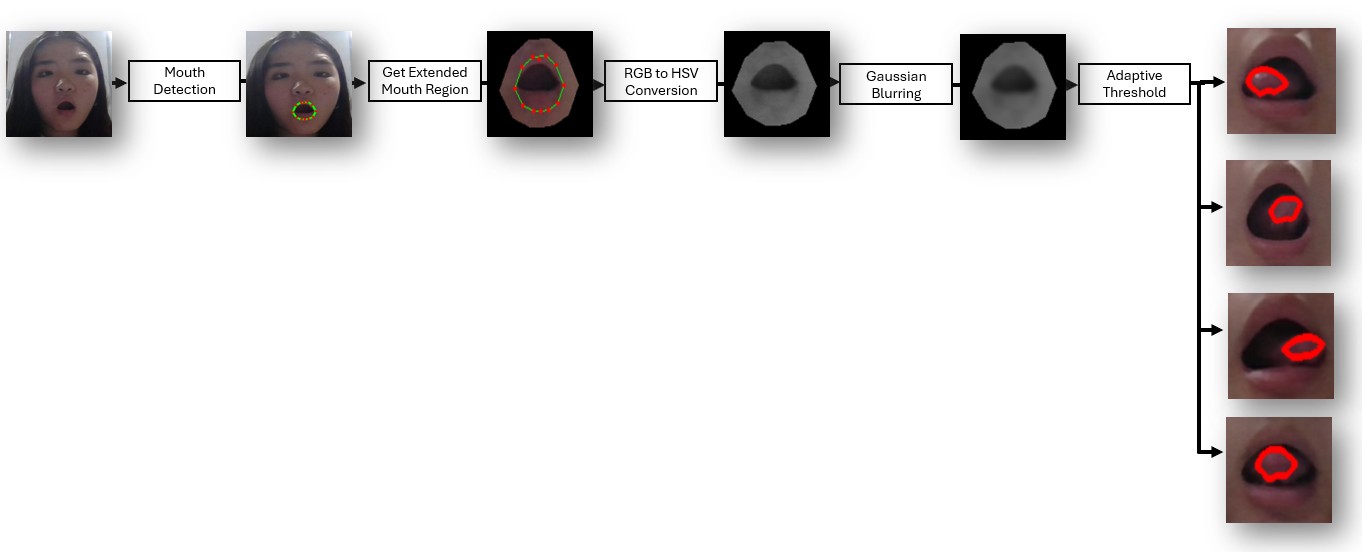
Processing Pipeline
The tongue segmentation algorithm follows a structured multi-step pipeline to ensure robust detection and minimal noise interference. First, Dlib’s facial landmark detection is used to detect the face and extract the mouth region. To improve detection robustness, the mouth region is expanded by approximately 20%, capturing additional relevant pixels around the tongue area. The image is then converted from RGB to HSV, allowing the V channel to be used for intensity-based segmentation. To further reduce noise, a Gaussian blur with a kernel size of 11×11 is applied. Next, an adaptive thresholding method is implemented in the extended mouth region to get the tongue region.
Tongue Orientation Recognition Using Concentric Mouth Contours
Accurately detecting tongue orientation is essential for precise gesture recognition in Tonguage. This algorithm leverages concentric mouth contours and cutline analysis to determine the tongue’s directional movement.
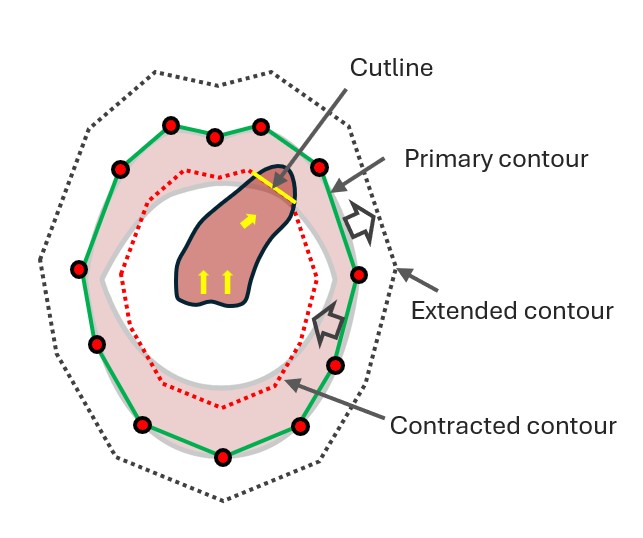
Concentric Contour Framework
The concentric contour framework consists of three hierarchical contours: the primary (outer lip) contour, an extended contour, and a contracted contour. The extended contour ensures that slight tongue protrusions beyond the lips are captured, preventing missed detections. The contracted contour is essential for orientation detection, as it defines the cutline—the intersection where the tongue crosses the inner lip boundary. By analyzing the cutline’s position and direction, the system accurately determines tongue movement, enabling precise real-time gesture recognition.
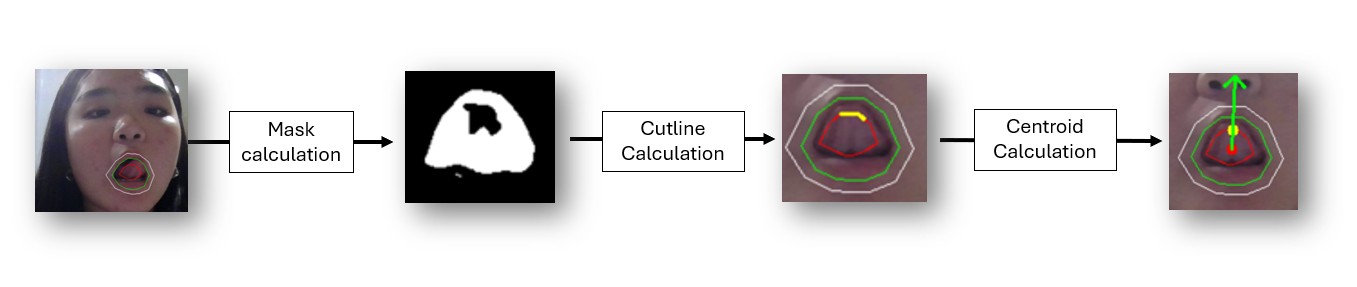
Processing Pipeline
The tongue orientation recognition pipeline begins by applying HSV conversion and adaptive thresholding to the extended contour to generate a binary mask for the mouth and tongue. The cutline is then identified as the intersection between the tongue mask and the contracted contour. To determine orientation, the centroid of the cutline points is calculated as the tongue’s contact position. Finally, an arrow from the mouth center to the cutline centroid defines the tongue’s movement direction, enabling precise gesture recognition in Tonguage.
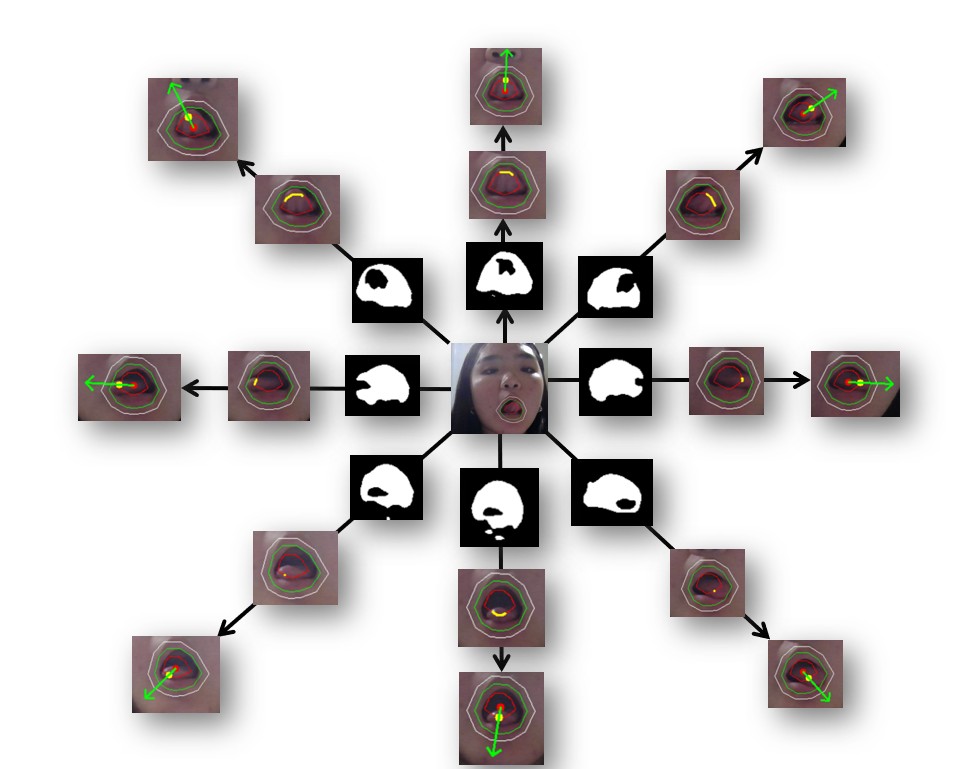
Tongue Tip Detection Using Orientation Ellipse Model
To enhance the Tonguage system's capability in tracking and detecting tongue movements with higher precision, we developed the Tongue Tip Detection Algorithm based on a novel Orientation Ellipse Model (OEM), a mathematical framework that dynamically estimates the tongue's shape and orientation.
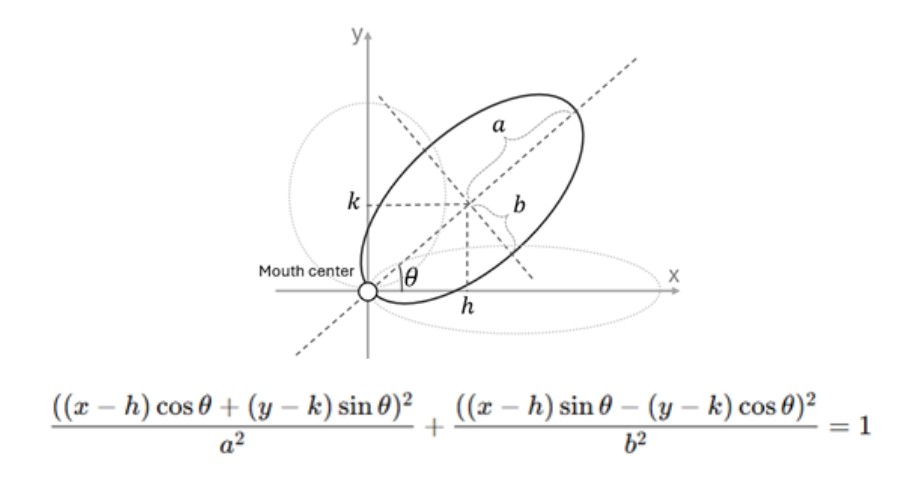
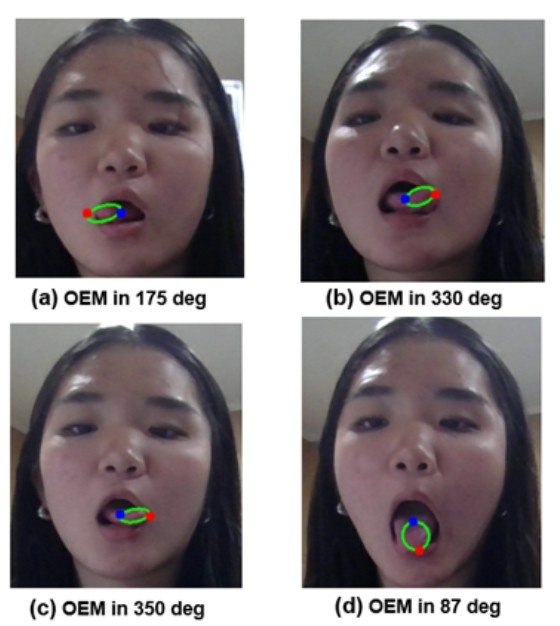
The model leverages the major-to-minor axis ratio of an ellipse to provide critical information about the tongue's positioning. When the tongue is positioned horizontally, the ratio between the major and minor axes (a/b) is high (a/b > 1), resulting in a flatter, elongated ellipse. Conversely, when the tongue moves vertically, this ratio decreases (a/b ≈ 1), transforming the ellipse into a more circular shape. This model provides an adaptive method for tracking tongue movement in real-time.
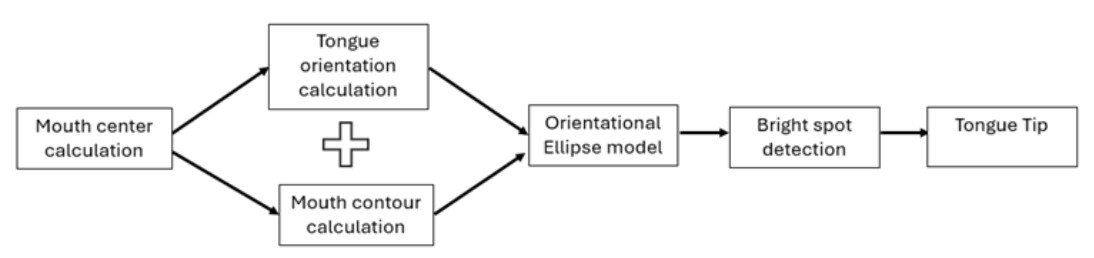
Processing Pipeline
The Tongue Tip Detection Processing Pipeline outlines the step-by-step procedure from mouth center calculation to final tongue tip identification. This structured approach allows for high-accuracy tracking of the tongue tip, facilitating precise gesture recognition and control within the Tonguage system. By employing the OEM-based detection algorithm, the system can effectively detect and track tongue movements, making it a highly robust and efficient tool for hands-free interaction.
Open Mouth Detection Using Mouth Aspect Ratio
The first critical step in the Tonguage system is the detection of the mouth within a given facial image. This process utilizes the modified Dlib library, which is based on an ensemble of regression trees trained to estimate facial landmark positions directly from pixel intensities. The Dlib library offers a real-time detection capability by identifying 68 key facial landmarks, including points on the mouth and lips, which are crucial for tracking the user's tongue movements.
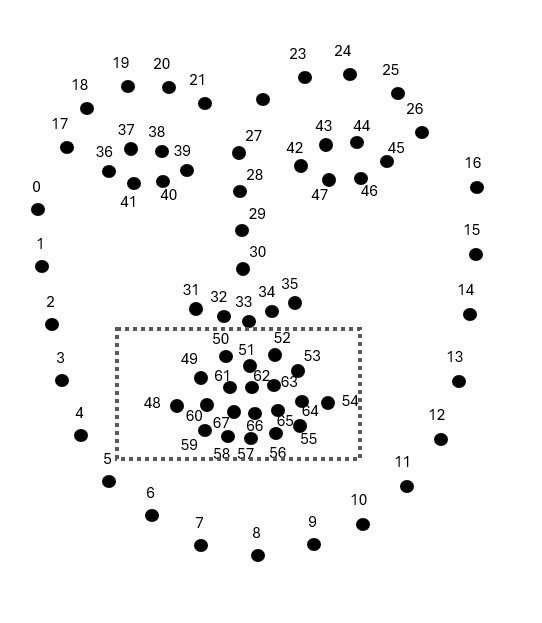
The detection process begins by locating the face within the image, followed by identifying the relevant facial landmarks. Once the mouth and lips are detected, the mouth aspect ratio (MAR) is calculated to determine whether the mouth is open or closed. The MAR is a geometric feature extracted from the distance between specific facial landmarks around the mouth. By analyzing the aspect ratio, the system can distinguish between different states of mouth openness, which is essential for interpreting tongue gestures accurately.

Eye Blink Detection Using Eye Aspect Ratio (EAR)
In addition to tongue-based input, the Tonguage system supports multiple modes of interaction to offer greater flexibility and improve accessibility. To further enhance its functionality, we developed an Eye Blink Detection Algorithm using the Eye Aspect Ratio (EAR). By integrating eye blink detection, Tonguage can utilize additional inputs, such as blinks, to trigger specific actions, such as selecting or clicking, in conjunction with tongue gestures. This multimodal approach enables users to interact with the system more naturally and intuitively, providing a seamless and hands-free experience.
Eye blinks can be an effective method for executing commands, such as simulating mouse clicks or activating other system functions. In this context, a blink serves as a clear, discrete action that users can perform without requiring significant effort. Using eye blinks as an input method enables precise control, reducing the need for continuous, manual input, and minimizing the risk of unintended actions. This functionality adds another layer of usability to Tonguage, making it ideal for users who may have limited motor function but still retain control over eye movements.
EAR Definition and Detection
The EAR is defined as the ratio of distances between specific landmarks on the eye, which are part of a set of key facial points detected by computer vision algorithms. Specifically, the EAR measures the vertical distance between the upper and lower eyelids relative to the horizontal distance between the eyelids. When the eye is open, the EAR value is higher, while a closed eye leads to a significantly lower EAR value. This ratio provides a reliable method for distinguishing between eye states and detecting blinks in real time.
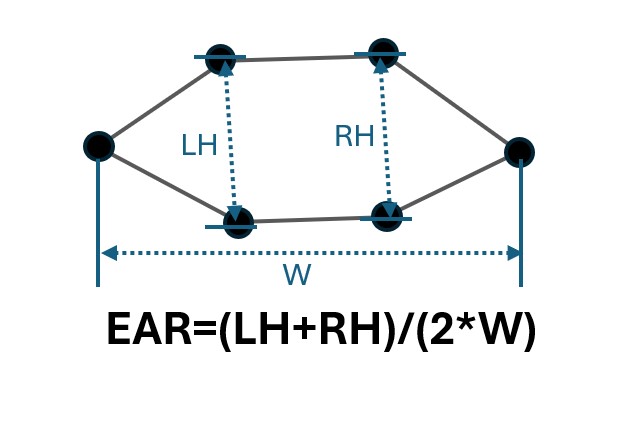

In the Tonguage system, the EAR-based eye blink detection algorithm is utilized to detect intentional blinks. A time threshold is implemented to differentiate between voluntary blinks and involuntary ones. When the EAR remains below a predefined value for a specified duration, it is recognized as an intentional blink, enabling users to perform actions like clicking or selecting.